@flaviobarros já encontrei a fundamentação do algoritmo:
2 curtidas
Desculpa pessoal, postei ontem a noite mas só consegui voltar agora! Então, o algoritmo é esse mesmo, é um cluster hierárquico. Mas mesmo um método como o Kmeans deve dar algo interessante. Com relação a ele ser na vertical, vou procurar como inverter, mas por hábito eu sempre usei assim mesmo 
Agora por fim, eu fiz um programinha em R. O R é uma linguagem de programação de nicho, muito usada para ciência de dados e estatística. Eu retiro os dados do statusinvest via webscraping, então o processo todo é automatizado. Eu também calculo a magic fórmula mas dá para fazer basicamente o que quiser. Com o R é possível criar uma API que cospe isso aí e conectar em uma planilha. Mas vocês olhando esses clusters algo chamou a atenção?
2 curtidas
Eu já não enxergo tão bem. Dá para ver alguma coisa, mas realmente está ruim para ver.
Creio que essa só pegando as linhas do balanço.
Se não fizer os ajustes fica totalmente fora da realidade.
Será que seria possível disponibilizar uma planilha com os dados do statusinvest?
Se você for na busca avançada você consegue baixar o resultado em csv. Aí é só abrir em uma planilha. É isso que você queria?
1 curtida
caraca! não sabia dessa posibilidade, valeeeu mano!
bOA TARDE VITOR
Como faço para adicionar ativos a planilha ?
Como funciona aquelas colunas com estrela grande … pequena … poderia dar uma breve explicação ?
Muito obrigado

1 curtida
Tem comentarios nas colunas pra vc entender melhor, porém as estrelas são os 2 ratings que eu calculo baseado na minha opiniao. O primeiro é a média geometrica e o segundo a media aritmetica. As outras colunas são apenas os valores calculados seguindo as fórmulas que estão descritas no cabeçalho.
Pra adicionar ativos você pode me pedir, porém algumas vezes não é possível pois muitas fórmulas levam em conta que a empresa lucra. Muita gente ja entrou em contato comigo pra incluir ativos zicados e aí as fórmulas não funcionam…
Tem que pagar. Eu também não tenho acesso, porém se você acessar o smarttinvest você consegue ver a carteira do mes passado
fiz alguma besteira onde sumiu o filtro da primeira coluna que creio eu seja as ações que ja possuo, como habilito novamente ?
Aew Flavio… Vc falou falou e não falou nada…
Está agrupando as ações em que sentido? Baseado em PL? Não tem o nome em cada cluster pra gente entender que tipo de agrupamento foi usado.
Parece que vc só aplicou uma formula pronta sem saber nos explicar o que ela faz rsrs…
Os clusters não precisam ter nomes. Esses métodos não supervisionados tem essa característica. Você tem que analisar os agrupamentos e entender o perfil dos clusters, aí sim você poderia dar “um nome”. Mas as técnicas de agrupamento (ou cluster) não se resumem a uma fórmula, é um algoritmo. Mas obviamente isso é parte de um trabalho que eu estou fazendo e ainda não está completo. Mas eu tenho desenvolvido índices com base nessa metodologia e em geral as melhores empresas acabam batendo com os valuations. No futuro talvez eu publique algo mais completo.
Por fim, “Parece que vc só aplicou uma formula pronta sem saber nos explicar o que ela faz rsrs…”, bom eu sou professor e dou aula desse e outros assuntos, então acho que eu entendo bem desses métodos 
4 curtidas
De uma forma simplificada o @flaviobarros analisa os indicadores como sem fossem dimensões (x,y, e z) e verifica “de forma simplificada” as distâncias entre cada ponto verificando os que apresentam mais caraterísticas em comum e menor distancia (A famigerada hipotenusa do Pitágoras Raiz[(x0-x1)^2+(y0-y1)^2] nesta referencia montada pelos indicadores.
Uma forma 2D de análise é como segue:
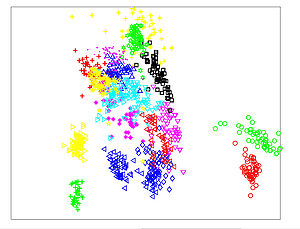
@flaviobarros se falei alguma besteira pode me corrigir.
5 curtidas
Sim! No geral é essa a ideia mesmo. Os detalhes principais dessa técnica é que o vetor de características que representa o objeto tem que ser a melhor representação possível. Se isso for verdade as distâncias entre os objetos serão ótimas referências de semelhança. Aí a única coisa que eu gostaria de acrescentar é que, uma vez que você calculou as distâncias dois a dois, para formar os clusters, tanto você pode usar métodos aglomerativos, tipo o hierárquico que eu usei, ou métodos de partição. A diferença é que nos métodos aglomerativos você começa formando pares e vai incluindo até chegar no grupão, por isso que o dendrograma fica daquele jeito. Agora nos métodos de partição você “chuta” um centroide para os cluster (e isso você tem que definir de antemão, quer dizer, se você acha que serão 3 cluster você tem que fornecer o K = 3 no k-means por exemplo) e aí todos os pontos são associados a algum cluster. Aí você calcula o novo centroide e faz isso até os pontos estabilizarem em um cluster por mais de uma interação.
Agora já que ressuscitamos esse tema, no caso desse projetinho que eu fiz minha ideia era a seguinte: o vetor de múltiplos, tipo P/L, P/VP, PEG, ROE e etc, representariam muito bem uma empresa. Logo eu faria os clusters e acharia as empresas mais próximas. Isso obviamente não substituiria uma análise fundamentalista mas nos ajudaria a fazer um screening melhor, pois se há empresas que a gente analisou e sabe que são boas, eu poderia encontrar as mais “próximas” e daí talvez descobrir umas pérolas escondidas que seriam interessantes e estão fora do radar. Acho que isso seria bem razoável. A grande questão é se esse vetor de múltiplos é uma representação boa. No caso eu usei todos os múltiplos que tem no statusinvest.
3 curtidas
Creio que poderia analisar também as correlações existentes entre as variáveis para evitar redundâncias. Por exemplo quando considera PEG e P/L você esta pesando duas vezes o preço/lucro. Poderia fazer em relação ao P/L e G (crescimento).
1 curtida
Eu acabei fazendo isso com o PCA, mas de qualquer forma no caso do agrupamento incluir uma variável correlacionada não machuca tanto assim. Mas é sempre bom dar uma “resumida” nos dados e também ver a estrutura das variáveis. Fazendo o PCA você acaba vendo como certos múltiplos são muito relacionados.
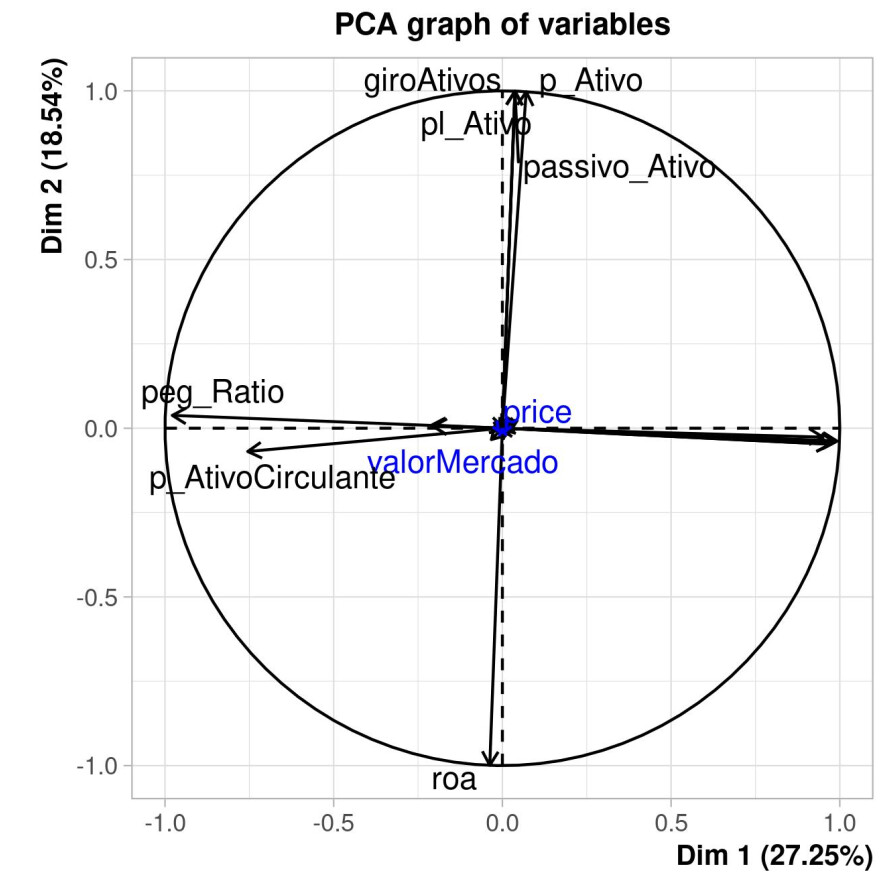
Essas variáveis sem label são P/L, ev/Ebit e etc, e acaba sendo isso mesmo, PEG para um lado e elas para o outro. Só que essa estrutura fica muito evidente quando não filtra nada. Se filtrar as empresas que dão lucro aí a coisa fica um pouco menos clara.
OBS: só para quem for ver o gráfico entender, aí está no eixo X a componente principal 1 (Dim 1) que captura 25,25% da variância total, contra a componente principal 2 (dim 2) que captura 18,54% da variância total. Elas são ortogonais e se nas duas primeiras componente for possível “projetar” as variáveis bem então elas funcionam como um resumo das colunas. No caso o azul são variáveis suplementares, no caso o valor de mercado e o preço da ação, então essas variáveis estão projetadas no plano das componentes principais, mas não entram na construção delas.
4 curtidas
Cara, que coisa linda que fizeste. Se postou no twitter me manda para eu retwittar https://twitter.com/RafaeldeJesusSM
Acho que é melhor mesmo abrirmos um tópico de Econometria/Quant para não floodarmos por aqui e acabar confundindo o pessoal que não gosta muito de “Rocket Science” .
5 curtidas
Precisa de um guia para leigos tipo aqueles livros amarelos.
5 curtidas